

In Echtzeit zu Erkenntnissen aus unstrukturierten Daten
Heutzutage werden täglich in jedem Unternehmen massive Mengen an Daten produziert, von denen ein beträchtlicher Anteil unstrukturierter Natur ist: Präsentationen werden erstellt, E-Mails geschrieben, Bilder verschickt, Produkte rezensiert usw.
Auch wenn die nachfolgende Statistik sicherlich nicht repräsentativ für alle Unternehmen ist, so verdeutlicht sie doch diesen Umstand hervorragend: Pro Minute werden auf Facebook 510.000 Kommentare verfasst und 293.000 Statusupdates veröffentlicht. Das sind alle 60 Sekunden 800.000 unstrukturierte Datensätze.
Einen Ansatz, unstrukturierte Daten in Echtzeit zu verarbeiten, zu analysieren und Erkenntnisse aus ihnen zu gewinnen, durften wir im November auf der Predictive Analytics World in Berlin und zuvor auf der ML Conference in München präsentieren. Diesen Ansatz wollen wir nachfolgend darlegen.
Anforderungen an eine Plattform für Real-time Streaming Analytics
Es gibt bestimmte nichtfunktionale Anforderungen an eine Plattform, die dazu in der Lage sein soll, Daten (auch, aber nicht ausschließlich) in unstrukturierter Form verarbeiten zu können.
Performance: Ein hoher Durchsatz an Daten muss mit geringer Latenz verarbeitet werden können, sonst wird das Ziel, Daten in Echtzeit zu verarbeiten, klar verfehlt.
Betrieb: Einfache Deploymentprozesse der einzelnen Komponenten und Schnittstellen, die für das Monitoring der KPIs angefragt werden können, erleichtern die betrieblichen Aspekte.
Skalierbarkeit: Vielleicht ist es initial nur ein Use Case, den Sie umsetzen wollen. Im Erfolgsfall wird dieser Use Case aber wachsen oder neue Use Cases wollen über die Plattform realisiert werden. Somit ist es unabdingbar, dass die Plattform von Beginn an auf diesen Ausbau ausgelegt ist.
Ausfallsicherheit: Insbesondere bei der Umsetzung von business-kritischen Use Cases ist es von zentraler Wichtigkeit, dass alle Komponenten der Plattform voneinander unabhängig ausfallsicher aufzusetzen sind, um Datenverlust vorzubeugen.
Sicherheit der Daten, Governance & Mandantenfähigkeit: Nicht erst mit Einführung der DSGVO sind Sicherheit und Schutz der Daten Kernaspekte, die eine datenverarbeitende Plattform erfüllen muss. Ebenso zentral ist die Möglichkeit, mehrere Mandanten mit genau denjenigen Daten, die sie benötigen und auf die sie auch zugreifen dürfen, bedienen zu können.
Erweiterbarkeit: Nicht nur der generelle Ausbau einer Plattform hinsichtlich ihrer Skalierbarkeit ist wichtig, sondern auch die Fähigkeit, über mehrere Data Centers laufen zu können. In einigen Branchen ist dies eine zentrale Anforderung, um auch im Notfall den Betrieb gesichert zu haben.
Exemplarischer Use Case: Echtzeitanalyse von Kundenrezensionen
Wie diese Anforderungen mit reinen Open Source Tools umgesetzt werden können, wurde bei den beiden Konferenzen anhand eines exemplarischen Use Cases gezeigt. Bei der Demo dieses Use Cases wurde ein kontinuierlicher Strom an Daten – Kundenrezensionen – simuliert, der über Beats* und Kafka von Spark eingelesen wurde, um die Bewertungen anhand des verfassten Textes in positive oder negative Bewertungen zu klassifizieren. Das Ergebnis wird zusammen mit der Rezension wieder in ein Kafka-Topic geschrieben, von wo aus Logstash* die analysierten Daten abholt und in einen Elasticsearch*-Index schreibt, der über Kibana* visualisiert werden kann.
Betrachtet man alle Komponenten, ergibt sich folgende Blaupause für den Aufbau einer solchen Echtzeitanalyseplattform:
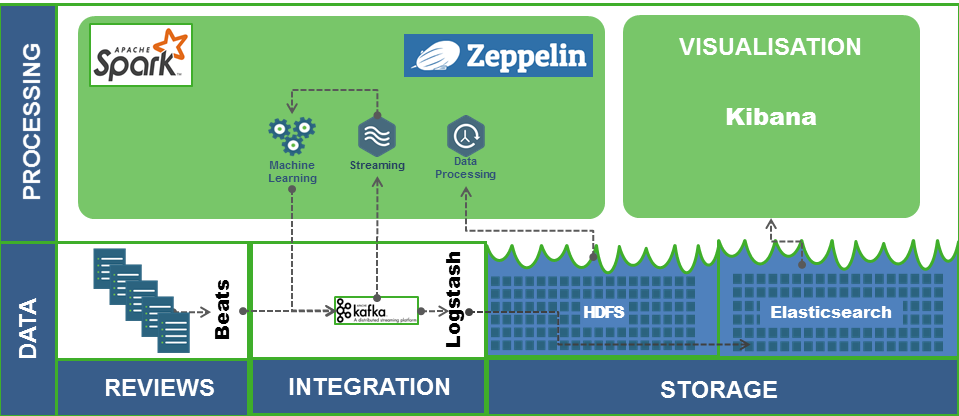
Die hier eingesetzten Open Source Tools sind nur eine von mehreren Möglichkeiten, eine solche Plattform umzusetzen. Bei einem konkreten Projekt kann es beim Einsatz des ein oder anderen Bausteins Überlegungen geben, die den Einsatz einer Alternative sinnvoll erscheinen lassen können.
Beats* und Logstash* sind beispielsweise zwei Tools, die sehr leichtgewichtig und einfach zu konfigurieren sind, sowie mit anderen Tools, wie z.B. Kafka sehr gut kombinierbar und integrierbar sind. Sollten diese jedoch an ihre Grenzen stoßen, was ihre Skalierbarkeit angeht, hieße eine logische Alternative Apache NiFi. NiFi wäre auch in der Lage als Ersatz für Apache Kafka einzuspringen. Ein Vorteil dieser Variante wäre das komplette Handling der Datenintegrationsschicht von einem einzigen Tool, was für einen einfacheren Betrieb sprechen kann.
Ein bisher nicht genanntes Tool, Apache Zeppelin, ist als Tool zum Prototyping für den Machine Learning Teil des Use Cases in der Architekturübersicht genannt. Zeppelin bringt von Haus aus volle Spark-Unterstützung mit, was Zeppelin gerade im Zusammenspiel mit Spark hervorragend eignet.
Zu guter Letzt bilden Elasticsearch* als hochskalierbarer Suchserver und Kibana* als Visualisierungsschicht diejenigen beiden Komponenten, die dafür sorgen, dass die Analyseergebnisse echtzeitnah eingesehen werden können, um geeignete Aktionen daraus abzuleiten.
Erkenntnisse aus der Echtzeit-Analyse von unstrukturierten Rezensionstexten
Doch was sind Erkenntnisse in Echtzeit und wie können sie genutzt werden? Hat man eine Plattform, die in Echtzeit den Inhalt Kundenrezensionen analysieren kann, lassen sich damit unterschiedlichste Ansätze verfolgen:
- Produkte, die inhaltlich positiv bewertet werden, können in einem Online-Shop geboostet werden, um diese bevorzugt den Kunden bei ihren Suchanfragen anzubieten. Gleichzeitig können diejenigen Produkte, die inhaltlich tendenziell negativ bewertet werden als weniger relevant eingestuft werden.
- Rezensenten, die häufig inhaltlich positive Bewertungen abgeben, können z.B. durch Gutscheine belohnt werden, um sie zu motivieren, weiter hilfreiche Texte für angebotene Produkte zu verfassen.
- Wird über die Analyse ermittelt, dass persönliche oder politische Ziele verfolgt werden, können diese automatisiert herausgefiltert werden, um nicht für Kunden sichtbar zu werden.
Dies sind lediglich drei Beispiele aus dem E-Commerce. Doch auch in anderen Branchen lassen sich relevante Use Cases abbilden, die mit der Echtzeit-Analyse von unstrukturierten Inhalten umgesetzt werden können:
- Fraud Detection bei Kreditkartenumsätzen: Manchmal lassen sich Muster erkennen, die rein auf Merkmalen basieren, wie z.B. von wem, wann und wo ein Umsatz getätigt werden. Wenn der zu einem Umsatz gehörige unstrukturierte Teil noch als zusätzliches Merkmal analysiert wird, lassen sich bessere Vorhersagen treffen, wann ein Umsatz ein Betrugsfall ist und wann nicht.
- Klassifikation von Transaktionen in Echtzeit: Dem Kunden im Online-Banking transparent zu machen auf welche Bereiche sich seine Ausgaben und Einnahmen verteilen, ist ein Mehrwert, den noch nicht jedes Finanzinstitut für sich entdeckt hat. Die Klassifikationsarbeit, die dafür automatisiert gemacht werden muss, muss in Echtzeit geschehen, damit der User dies für getätigte Transaktionen direkt einsehen kann.
- Extraktion von Entitäten zur Inhaltsanreicherung von Texten: Für alle verfassten Texte gilt, dass sie üblicherweise Entitäten enthalten, mit deren Hilfe sie leichter zusammengefasst werden können bzw. wodurch einem Leser schnell vermittelt werden kann, um was es sich bei diesem Text inhaltlich dreht. Diese Entitäten während dem Verfassen auszuzeichnen ist jedoch Aufwand, der automatisiert werden kann, indem entweder bereits während dem Verfassen oder direkt nach dem Verfassen analysiert wird, welche Entitäten im Text enthalten sind.
An diesen Beispielen wird deutlich, dass der Einsatz einer Plattform, die in Echtzeit unstrukturierte Daten verarbeiten kann, nicht nur in einer Branche lohnenswert sein kann.
Haben auch Sie eine Idee, wie der Einsatz einer derartigen Plattform Ihren Geschäftserfolg steigern kann und benötigen Unterstützung? Dann nehmen Sie Kontakt mit uns auf!
Wollen Sie mehr erfahren zum Thema Data Analytics, speziell für den Bereich E-Commerce? Dann könnte die Studie Data Analytics im E-Commerce für Sie interessant sein!
Bernard Marr – How Much Data Do We Create Every Day? The Mind-Blowing Stats Everyone Should Read – https://www.forbes.com/sites/bernardmarr/2018/05/21/how-much-data-do-we-create-every-day-the-mind-blowing-stats-everyone-should-read/
*) Elastic, Elasticsearch, Logstash, Beats und Kibana sind Handelsmarken der Elasticsearch BV, registriert in U.S. und anderen Ländern. Alle Verwendungen der Begriffe Elastic, Elasticsearch, Logstash, Beats und Kibana beziehen sich auf diese Handelsmarken und haben lediglich beschreibenden Charakter.


